员工爆出Llama 4质量差的原因是混合测试集进行跑分作弊刷榜 Meta否认这种说法
早前社交媒体集团 Meta 推出新的人工智能模型 Llama 4 系列,据 Meta 称这些新模型在能力方面达到或超越竞争对手,例如谷歌 Gemini、Anthropic Claude、OpenAI GPT-4o 以及 DeepSeek-V3 等。
但在模型发布后不少 AI 开发者下载进行测试后发现 Llama 4 模型并未达到预期的能力,同时网上也出现自称是 Meta AI 团队的员工爆出这些模型属于紧急发布,很多地方并未完成优化。
随后就有网友爆出 Llama 4 的纸上数据是 Meta 精心调配而来,也就是针对 AI 基准测试进行针对性的优化从而获得更好的成绩进行刷榜,这与各种智能手机测试性能时的跑分作弊完全相同。

对于这种说法 Meta 进行否认,Meta GenAI 副总裁 Ahmad AI-Dahle 发帖表示:
Meta 在测试集中训练 Llama 4 Maverick 和 Llama 4 Scout 的说法根本不是事实。一些用户发现托管在不同云服务商的模型表现残次不齐,由于我们在模型准备就绪后将将其删除,因此我们预计所有的公开部署还需要几天才能完成,同时我们将努力修复错误并吸引合作伙伴。
在 AI 基准测试中,测试集是用来评估模型训练后性能的数据合计,在测试集上训练可能会误导性的夸大模型的基准测试分数,也就是针对测试集进行训练很可能让模型得分看起来非常强大。
这件事的起因来自中文论坛一亩三分地 (1Point3Acres),该论坛主要用户是位于北美的中国留学生和工作者,名为 @dliudliu 的用户自称是 Meta GenAI 团队的员工。
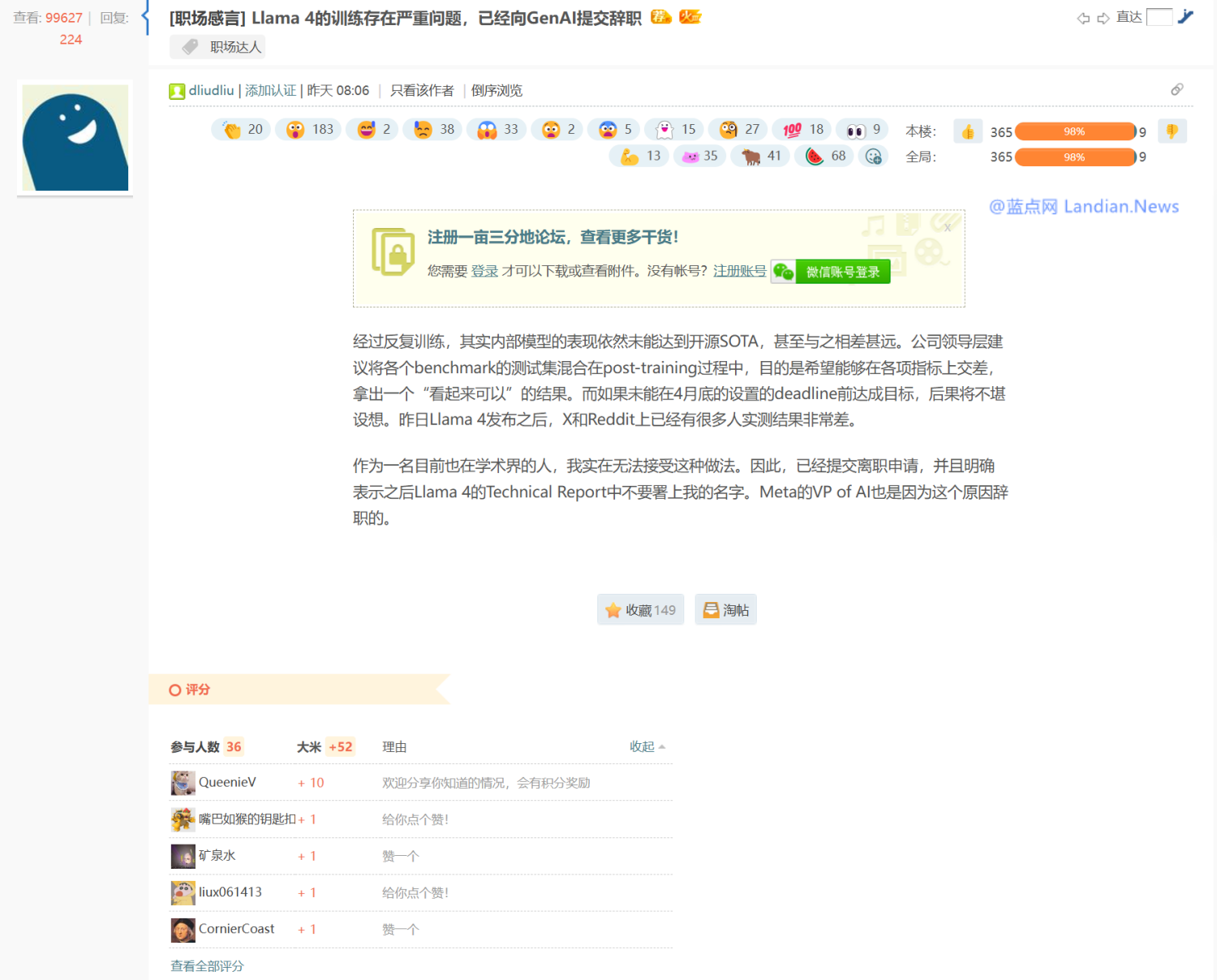
这名网友表示 Llama 4 经过反复训练都没能达到开源模型的水平,于是公司领导建议将测试集数据混合到训练过程中,从而达到各项指标拿出一个看起来可以的结果,因为如果没能在 4 月底前达成目标后果将不堪设想。
网友自称也是学术界的人,实在无法接受这种做法所以提交了离职申请,还表示之后的 Llama 4 技术报告中不要署名,早前 Meta GenAI VP 辞职可能也是这个原因。